点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:phantom | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/567999703
本文介绍我们 NeurIPS 2022 关于 Spectral Compressive Imaging (SCI)重建的工作:
《Degradation-Aware Unfolding Half-Shuffle Transformer for Spectral Compressive Imaging》

文章:https://arxiv.org/abs/2205.10102
代码(已开源):
https://github.com/caiyuanhao1998/MST
这个github仓库是一个针对 Snapshot Compressive Imaging 重建的工具包,集成了超过12种深度学习算法。我们之前的工作如 MST, CST, MST++, HDNet 也都在这个github仓库中开源。本文也是我们做的 Transformer in SCI 系列的第三个工作。
1. 简介
单曝光快照压缩成像(Snapshot Compressive Imaging,SCI)的任务是将一个三维的数据立方块如视频(H×W×T)或高光谱图像(H×W×λ)通过预先设计好的光学系统压缩成一个二维的快照估计图(H×W)从而大幅度地降低数据存储和传输的开销。常见的单曝光快照压缩成像系统有 Coded Aperture Snapshot Spectral Compressive Imaging (CASSI),如下图所示
图1 单曝光快照压缩成像光学系统那么在 SCI 中一个至关重要的问题就是如何从被压缩过后的二维快照估计图重建出原始的三维数据,当前主流的方法大都基于深度学习,可以分为两类:端到端(End-to-end)的方法和深度展开式(Deep Unfolding)的方法。端到端的方法直接采用一个深度学习模型,去拟合一个从 2D 快照压缩估计图到 3D 高光谱数据的映射。这种方法比较暴力,确实可解释性。深度展开式方法将神经网络嵌入到最大后验概率(Maximum A Posteriori,MAP)模型中来迭代地重建出高光谱图像,能更好地和光学硬件系统适配。因此,本文主要研究深度展开式算法。当前这些方法主要有两大问题:
当前的深度展开式框架大都没有从 CASSI 中估计出信息参数用于引导后续的迭代,而是直接简单地将这些所需要的参数设置为常数或者可学习参数。这就导致后续的迭代学习缺乏蕴含 CASSI 退化模式和病态度信息指导。
当前的 Transformer 中全局的 Transformer 计算复杂度与输入的图像尺寸的平方成正比,导致其计算开销非常大。而局部 Transformer 的感受野又受限于位置固定的小窗口当中,一些高度相关的 token 之间无法match。
为了解决上述两个问题,我们提出了首个深度展开式的Transformer。我们贡献可以概括为:
首先,我们推导出了一个能够感知 CASSI 退化模式与病态度的深度展开框架,它从压缩估计图和编码掩膜中估计出信息参数来引导后续的迭代学习。
接着,我们设计了一个能够同时捕获局部和全局依赖关系的 Transformer 并且计算复杂度相较于全局的Transformer而言,大幅减低。
最终,我们将我们设计的 Transformer 嵌入到我们推导的深度展开框架中来极大提升光谱图像重建的效果。我们的算法在使用更低参数量和更少计算量的前提之下,性能大幅度地超过了前人的方法。
2. 方法
2.1 CASSI 压缩退化的数学模型
我们定义向量化后的压缩估计图为 y , 被偏移后的输入数据为 x, 传感矩阵为 φ ,则 CASSI 的退化数学模型为
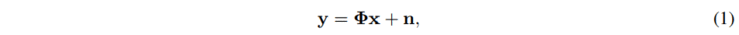
其中的 n 表示成像时产生的随机噪声,同样地,它也经过了向量化。
2.2 退化可感知的深度展开框架
图2 退化可感知的深度展开式数学框架我们首先推导出一个 CASSI 退化模式和病态度可感知的深度展开框架,Degradation-Aware Unfolding Framework (DAUF),如图 2 所示。它以最大后验概率为理论基础来进行推导。结合公式(1),我们可以得到 CASSI 的最大后验概率能量优化函数为:
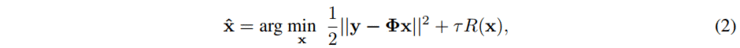
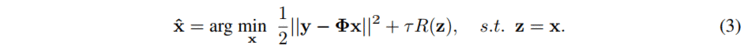
引入辅助变量 z 之后,我们可以得到
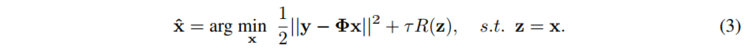
为了得到展开式的推导,同时使迭代过程更加简单,能够更快地收敛,我们对公式(3)采用 Half-Quadratic Splitting (HQS)算法进行展开,得到:
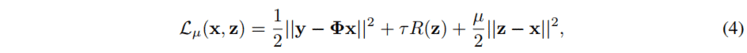
我们对公式(4)中的 x 和 z 进行解耦,从而得到两个迭代的子问题如下:

其中的 x 项有一个闭式解:
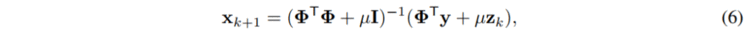
其中 I 是恒等矩阵,上述闭式解涉及到矩阵求逆,对计算机不友好。为简化矩阵求逆运算,我们做了以下推导:
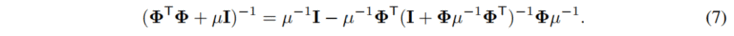
将公式(7)插入到公式(6),我们可以得到:


2.3 半交互式 Transformer
图3 半交互式 Transformer 的网络结构图2.3.1 网络整体结构
我们半交互式 Transformer (Half-Shuffle Transformer,HST)的整体结构如图3 (a) 所示,采用一个 U 形网络,包含 一个 Encoder,Bottleneck,Decoder。其中基本单元是 Half-Shuffle Attention Block (HSAB)。HSAB中最重要的模块是 Half-Shuffle Multi-head Self-Attention (HS-MSA)。
2.3.2 Half-Shuffle Multi-head Self-Attention

3. 实验
3.1 定量实验对比
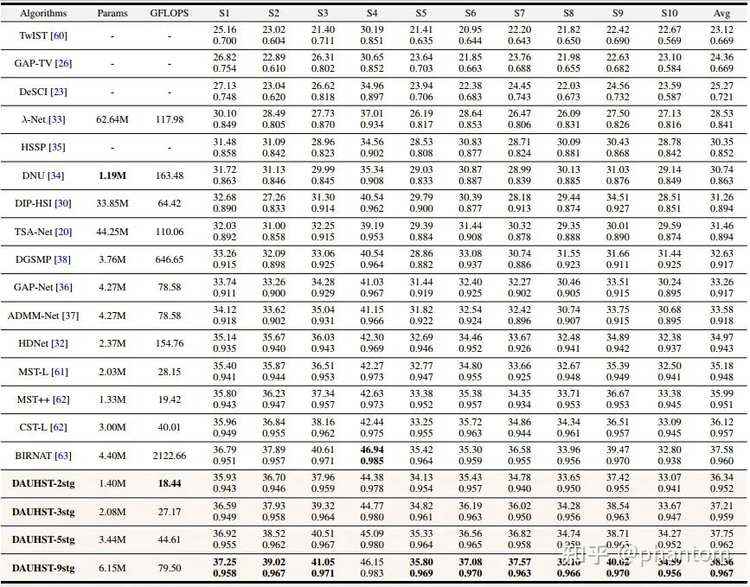
表1 定量实验对比图定量实验对比如表 1 所示,我们的 DAUHST 以更低的计算量和参数量显著超越了之前 16 种 state-of-the-art 方法。我们的方法比先前最好的方法 End-to-end 方法 CST-L 和 Deep Unfolding 方法 BIRNAT 要分别高出 2.24 和 0.78 dB。
图4 不同 Deep Unfolding 方法的 PSNR - FLOPS 对比图相较于先前的 Deep Unfolding 方法,我们绘制了 PSNR - FLOPS 坐标图比较 DAUHST 和其他 Deep Unfolding 方法的 性价比。如图4所示。我们的方法在消耗相同计算量的情况下比先前方法要高出 4 dB。
3.2 定性实验对比
图5 仿真数据集上的视觉对比结果在仿真数据集上的定性结果对比如图5所示。左上角是RGB图像和快照估计图(Measurement)。下方四行图像是不同方法重建的四个波长下的高光谱图像。右上角的图像是下方图像中黄色框框内的放大图。从重建的高光谱图像来看,我们的方法能更好地恢复出细节内容和纹理结构,请注意对比小立方块区域。a 和 b 曲线对应着 RGB 图像的两个绿色框的区域的光谱强度曲线,可以看出,我们的 DAUHST 与 Ground Truth 的曲线最为接近。
图6 真实数据集上的视觉对比图图6 展示的是各类方法在真实数据集上的对比。可以看出只有我们的方法能够在各种波长的光谱上稳定地重建出小花并同时抑制噪声的生成。
4. 总结
本文是我们 SCI 系列代表作的第五个,也是 NeurIPS 上边首次有 SCI 重建的工作。SCI 重建作为新兴的 low-level 方法这两年迅猛发展,希望能够看到有更多的人能够加入的这个 topic 的研究,毕竟新的领域有更多出成果的机会。另附上我们先前在 CVPR 2022 和 ECCV 2022 上的两个工作 MST 和 CST 的解读链接:
ECCV 2022 | 清华等提出CST:首个嵌入光谱稀疏性的Transformer
CVPR 2022 & NTIRE 2022冠军方案!MST:多快好省的高光谱图像重建
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看











 京公网安备 11010802041100号
京公网安备 11010802041100号